最近这段时间一直在学习docker的使用,以及如何在docker中使用tensorflow.今天就把在docker中如何使用tensorflow记录一下.
docker安装
我是把docker安装在centos 7.4操作系统上面,在vmware中装的centos,vmware中安装centos很简单.具体的网络配置可以参考vmware nat配置.docker安装很简单,找到docker官网,直接按照上面的步骤安装即可.运行docker version查看版本如下
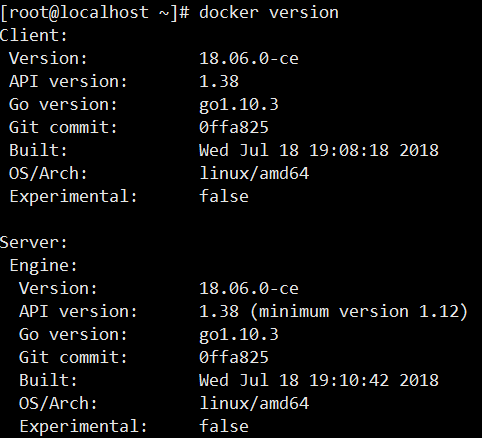
因为docker 采用的是客户端/服务端的结构,所以这里可以看到client以及server,它们分别都有版本号.
tensorflow
在docker中运行tensorflow的第一步就是要找到自己需要的镜像,我们可以去docker hub找到自己需要的tensorflow镜像.tensorflow的镜像主要分两类,一种是在CPU上面跑的,还有一种是在GPU上面跑的,如果需要GPU的,那么还需要安装nvidia-docker.这里我使用的是CPU版本的.当然我们还需要选择具体的tensorflow版本.这里我拉取的命令如下:
1 | docker pull tensorflow/tensorflow:1.9.0-devel-py3 |
拉取成功之后,运行docker images可以看到有tensorflow镜像.
tensorflow在docker中使用
1 | docker run -it -p 8888:8888 --name tf-1.9 tensorflow/tensorflow:1.9.0-devel-py3 |
运行上面的命令,在容器中启动镜像.-p表示指定端口映射,即将本机的8888端口映射到容器的8888端口.--name用来指定容器的名字为tf-1.9.因为这里采用的镜像是devel模式的,所以默认不启动jupyter.如果想使用默认启动jupyter的镜像,那么直接拉取不带devel的镜像就可以.即拉取最近的镜像docker pull tensorflow/tensorflow
启动之后,我们就进入了容器,ls / 查看容器根目录内容,可以看到有run_jupyter.sh文件.运行此文件,即在根目录下执行./run_jupyter.sh --allow-root,--allow-root参数是因为jupyter启动不推荐使用root,这里是主动允许使用root.然后在浏览器中就可以访问jupyter的内容了.
创建自己的镜像
上面仅仅是跑了一个什么都没有的镜像,如果我们需要在镜像里面跑我们的深度学习程序怎么办呢?这首先做的第一步就是要制作我们自己的镜像.这里我们跑一个简单的mnist数据集,程序可以直接去tensorflow上面找一个例子程序.这里我的程序如下:
1 | # Copyright 2015 The TensorFlow Authors. All Rights Reserved. |
这里我在原来的程序基础上面稍微改了下,因为我已经提前将数据下载好了,所以我让程序直接读取本机指定目录下的训练数据,同时增加了日志文件输出.这是为了在公司的容器云平台上测试获取容器输出文件
编写Dockerfile
我们可以在我们的用户目录下,创建一个空的文件夹,将mnist数据集以及程序文件都拷贝进这个文件夹下.其实数据集应该是放在数据卷中,但是这里为了方便,我直接将训练数据打进了镜像中.然后创建Dockerfile,文件内容如下
1 | FROM tensorflow/tensorflow:1.9.0-devel-py3 |
即Dockerfile文件中最后一行表示容器启动的运行的命令
build镜像
1 | docker build -t tf:1.9 . |
-t参数指定镜像跟tag,最后的.指定了镜像中的上下文.构建完之后使用docker images可以查看多了tf:1.9镜像
运行镜像
运行下面的命令,运行上一步构建好的镜像
1 | docker run -it --name test tf:1.9 |
然后就能够看到训练的输出.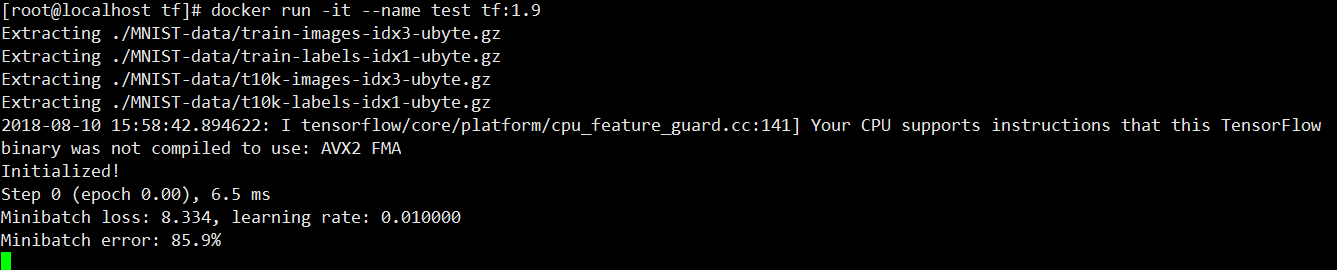
同时可以在看一个连接,进入容器,即运行下面命令
1 | docker exec -it test /bin/bash |
可以看到如下内容
即看到了cnn_mnist.log的日志输出文件